مجازی سازی دسکتاپ
مجازی سازی دسکتاپ(DESKTOP VIRTUALIZATION)
امروزه بیشتر سازمان ها از محیط هایی استفاده می کنند که در آنها کامپیوتر های فیزیکی و PC ها مستقر هستند. در این محیط ها که به احتمال زیاد همه ی ما با آن آشنا هستیم، وجود PC هایی که هر کدام به طور مستقل قطعات تشکیل دهنده ی خود را دارند (مادربرد، رم، پردازنده، پاور و…) و آسیب هایی که این قطعات با آنها درگیر هستند منجر به مصرف انرژی، هزینه ی نگهداری و استهلاک بالا می شوند در حالی که فضای مدیریت مناسبی را هم ارائه نمی دهند. از طرفی در سمت کاربران تجهیزاتی وجود دارد که هر کدام از آن ها فضای فیزیکی زیادی را اشغال می کنند. اما چه راهکاری برای غلبه بر این معضلات در محیط کاری شما وجود دارد؟
مجازی سازی دسکتاپ چیست؟
یکی از کارآمدترین راهکارهای مجازی سازی، مجازی سازی دسکتاپ (VDI) می باشد. در مجازی سازی دسکتاپ به هر کلاینت یک ماشین مجازی اختصاص داده می شود که متناسب با نیاز کلاینت، منابع پردازشی لازم در اختیار ماشین قرار می گیرد و سیستم عامل بر روی آن نصب می شود. در واقع کاربران روی میز کار خود از این سیستم عامل ها استفاده می کنند، در حالی که پردازش های مربوط به آن ها روی سرور انجام می شود. به عبارتی مجازی سازی دسکتاپ جدا سازی مکان قرارگیری سیستم عامل از محیط کاربری و انتقال آن به دیتاسنتر است.
سرورها برای به کارگیری مجازی سازی دسکتاپ و ساخت ماشین های مجازی که قابلیت های دسکتاپ را به صورت مجازی ارائه می دهند، از Hypervisor استفاده می کنند.
به سناریو زیر توجه کنید:
فرض کنید سازمان شما به 150 کلاینت نیاز دارد، برای رفع این نیاز دو راه در پیش رو دارید. در رویکرد اول که روشی سنتی است، باید دیوایس هایی مانند کیس، all in one و… تهیه شود که برای این تعداد کلاینت می تواند هزینه ی خرید و پیاده سازی بالایی را به همراه داشته باشد. هزینه های نگهداری و پشتیبانی از تجهیزات و مصرف انرژی آن ها از فاکتور های مهم در محاسبه ی مخارج سازمان می باشد. از طرفی با توجه به مشکلات موجود در تامین انرژی، امروزه یکی از مهم ترین کارهایی که هر شخص باید در انجامش کوشا باشد، صرفه جویی در مصرف انرژی است اما در این رویکرد 150 دستگاه وجود دارد که هر کدام استهلاک، هزینه ی نگهداری و مصرف انرژی خود را دارند. بنابراین اتلاف انرژی زیاد و مقرون به صرفه نبودن از نتایج رویکرد اول خواهد بود. رویکرد دوم، همان راهکار مجازی سازی دسکتاپ است که به شما اجازه خواهد داد، منابع پردازشی خود را در دیتاسنتر گردآورید. اگر سازمان شما از رویکرد دوم استفاده کند، ممکن است هزینه ی پیاده سازی آن برابر با رویکرد اول یا حتی بیشتر از آن شود، اما هزینه ی نگداری کمتری را در آینده به شما تحمیل خواهد کرد. برای دستیابی به درکی بهتر از این مسئله به مثال زیر توجه کنید:
اگر سازمان شما نیازمند ارتقای منابع پردازشی کلاینتها باشد، رویکرد اول برای خرید سخت افزار و نصب آن روی کلاینت به هزینه های بیشتری نیاز دارد، در حالی که در مجازی سازی دسکتاپ، با استفاده از فضای مدیریتی که مجازی سازی در اختیارتان قرار می دهد به راحتی می توانید منابع پردازشی و ذخیره سازی یک کلاینت را ارتقا دهید. با استفاده از مجازی سازی دسکتاپ شما می توانید در مصرف انرژی صرفه جویی کنید، هزینه های نگهداری را کاهش دهید، امنیت بیشتر، مدیریت بهتر و بهینه تری را روی سیستم هایتان داشته باشید.
توجه کنید که مجازی سازی دسکتاپ (bare metal) را با نوعی مجازی سازی که توسط نرم افزار هایی مانند VMware Workstation و Virtual Box در دسکتاپ انجام می شود، اشتباه نگیرید.
مزایای مجازی سازی دسکتاپ
مجازی سازی دسکتاپ مزایای زیادی برای فناوری اطلاعات و سازمان ها دارد. برخی از مهم ترین آن ها عبارت اند از:
- صرفه جویی در هزینه ها : از منظر فناوری اطلاعات، مجازی سازی دسکتاپ هزینه های مدیریت و پشتیبانی و زمان ایجاد یک دسکتاپ جدید را کاهش می دهد. کارشناسان معتقدند که نگهداری و مدیریت منابع در محیط مجازی سازی شده 50 تا 70 درصد از مجموع هزینه مالکیت (TCO) یک محیط فیزیکی را دربر می گیرد. سازمان ها معمولا برای صرفه جویی در این هزینه ها به مجازی سازی دسکتاپ روی می آورند.
- سهولت مدیریت : از آنجایی که در مجازی سازی همه چیز به صورت مرکزی مدیریت، ذخیره و محافظت می شود، مجازی سازی دسکتاپ نیاز به نصب، به روز رسانی، patch کردن برنامه ها، بک آپ گرفتن از اطلاعات و شناسایی ویروس ها در کلاینت های مختلف را از بین می برد. بنابراین مجازی سازی دسکتاپ به ساده سازی مدیریت برنامه های موجود کمک می کند. در مجازی سازی دسکتاپ می توان از کلاینت های قدیمی به عنوان ایستگاه های دریافت کننده سرویس دسکتاپ مجازی (Thin client) استفاده کرد. برخلاف کامپیوتر های شخصی که توان پردازشی، فضای ذخیره سازی و حافظه ی رم مورد نیاز برای اجرای برنامه ها را در داخل خود دارند، thin client ها به عنوان دسکتاپ های مجازی عمل می کنند و در بستر شبکه از توان پردازشی سرور موجود در شبکه بهره می برند.
- امنیت بیشتر : مدیریت بهینه ی موجود در دسکتاپ های مجازی، امکان اتصال دستگاه های ذخیره ساز قابل حمل به سیستم های thin client را نمی دهد مگر اینکه دسترسی این عملکرد به کاربران داده شود. به همین خاطر امکان درز اطلاعات، نفوذ بد افزار ها و باج افزار ها به این سیستم ها کاهش پیدا می کند. مطلب دیگری که امنیت محیط مجازی سازی شده را افزایش می دهد این است که تمامی اطلاعات سازمان حتی اطلاعاتی که کاربران در پروفایل خود ذخیره می کنند در دیتاسنتر ذخیره و نگهداری می شود و از آنجایی که داده های کاربر به صورت مرکزی و منظم پشتیبان گیری می شود، مجازی سازی دسکتاپ مزایای یکپارچگی داده را نیز فراهم می کند.
- بهره وری بیشتر : مجازی سازی دسکتاپ به کابران این امکان را می دهد که از طریق دستگاه های مختلف مانند دسکتاپ های دیگر، لپتاپ ها، تبلت ها و گوشی های هوشمند به برنامه ها و اطلاعات مورد نیاز دسترسی داشته باشند. این امر بهره وری را با ارائه اطلاعات مورد نیاز به کاربران در هر مکانی، افزایش می دهد. از طرفی اگر دستگاه یکی از کاربران آسیب دید از آنجایی که اطلاعات دسکتاپ به صورت locally ذخیره نمی شود، آن کاربر می تواند از دستگاه های دیگر برای دسترسی به دسکتاپ و رسیدگی به ادامه کارش استفاده کند.
vSphere به همراه operation management
سازمان شما برای پاسخگویی به نیازهای کسب و کارتان باید با کمترین هزینه، بهترین عملکرد برنامه ها و بالا ترین میزان دسترس پذیری آنها را ارائه کند. این همان مزیتی است که VMware vSphere از طریق operation management ارائه می کند.
مجازی سازی
vSphere به همراه operation management، مطمئن ترین پلتفرم مجازی سازی را به همراه قابلیت های بسیار مهم برای مانیتور کردن عملکرد و مدیریت ظرفیت های محیط مجازی سازی شده ارائه می کند. برای اینکه بهترین تصمیم را برای سازمان خود بگیرید، مواردی وجود دارند که باید آنها را بفهمید تا مجازی سازی سازمان شما به خوبی انجام شود.
VMware vSphere قابلیت ها و ویژگی های زیادی را دارد که مهم ترین آنها عبارت اند از:
در ادامه به این ویژگی ها می پردازیم.
1 – تکنولوژی اثبات شده
زمانی که شما از یک راهکار مجازی سازی در سازمانتان استفاده می کنید، می خواهید مطمئن باشید که محیط شما بر اساس یک تکنولوژی اثبات شده بنا شده و این راهکار به طور گسترده در سازمان های دیگر استفاده و از طرف ارائه دهنده، پشتیبانی شود. اینها مواردی است که از طریق مدیریت عملکرد ها در vSphere به دست می آید.
امروزه، بیش از نیم ملیون سازمان اطلاعات و برنامه های خود را به راهکارهای VMware سپرده اند. طبق گزارش Magic Quadrant سازمان گارتنر، VMware پنج سال متوالی در زمینه مجازی سازی سرور های x86 پیشرو بوده است.
VMware این اطمینان را به شما می دهد که بیش از 5000 برنامه روی پلتفرم vSphere تست و تایید شده که می توانید از آنها استفاده کنید، در میان این تعداد برنامه، یک اکوسیستم گسترده متشکل از بیش از 2000 تولید کننده نرم افزار مستقل از هم وجود دارد که ISV نام دارد.
این اکوسیستم به شما دسترسی به محصولات ISV را می دهد که قابلیت های vSphere را ارتقا و گسترش می دهند. تعداد زیادی از متخصصان VMware هم وجود دارند که می توانند به شما کمک کنند تا به سرعت و متناسب با نیازتان، به محیط مجازی سازی شده ایمن دست یابید.
2 – مدیریت یکپارچه
بازار مجازی سازی پر از ابزارهای مدیریتی است که برای سرورهای فیزیکی ساخته شده اند اما برای مدیریت سیستم های مجازی نیز استفاده می شوند. این موضوع مطابق با راهکار های VMware که برای محیط های مجازی و cloud هدفمند شده اند، نیست.
با استفاده از VMware، شما از مزیت های برنامه ای برخوردار خواهید شد که توسط اشخاصی که شناخت کاملی از محیطvSphere و نیاز سازمان ها برای مجازی سازی دارند، طراحی شده است. این شناخت در ویژگی های پیشرفته ای مانند اختصاص منابع به صورت پویا، load balancing، مانیتور کردن عملکرد، چک کردن سالم بودن سیستم و بهینه سازی ظرفیت ها گنجانده شده است.
به طور متوسط، سازمان هایی که از vSphere با operation management استفاده می کنند متوجه افزایش 30 درصدی صرفه جویی در سخت افزار، 34 درصدی در استفاده از ظرفیت ها و 36 درصدی در consolidation ratio نسبت به vSphereبدون operation management، می شوند.
برای گسترش بیشتر قابلیت ها، محیط vSphere طوری طراحی شده تا ابزار های third party بتوانند با VMware vCenter Server یکپارچه شوند که این موضوع برای محیط مجازی شما مدیریتی متمرکز را ارائه می کند.
3 – قابلیت اطمینان
هنگامی که فعالیت های کسب و کار شما به سرویس های فناوری اطلاعاتتان بستگی دارد، شما می خواهید مطمئن شوید که منابع محاسباتی قابل اطمینان و پیشبینی پذیری که برای مجازی سازی طراحی شده است را دارید. این یکی از مزیت هایvSphere به همراه operation management است.
اکثر راهکار های مجازی سازی از سیستم عامل های عمومی استفاده می کنند که برای ارائه قابلیت های مجازی سازی به آن یک hypervisor اضافه شده است. این می تواند یک مشکل باشد، چون اضافه کردن عملکرد مجازی سازی به یک سیستم عامل عمومی، پلتفرم مجازی سازی را در معرض خطرهای شناخته شده ی موجود در سیستم عامل های عمومی قرار می دهد.
این موضوع در مورد vSphere صدق نمی کند. vSphere با معماری legacy-free که از ابتدا برای مجازی سازی طراحی شده بود، به جای اینکه از طریق یک سیستم عامل عمومی با سخت افزار ارتباط داشته باشد، ارتباطی مستقیم با آن برقرار می کند (همان طور که در تصویر زیر نشان داده شده). این معماری به vSphere این امکان را می دهد که از بروز مشکلات مربوط به سیستم عامل های عمومی جلوگیری کند.
VMware vSphere که مستقل از سیستم عامل است به صورت مستقیم از منابع پردازشی استفاده می کند، که منجر به افزایش قابلیت اطمینان و کاهش مواجهه با مشکلات مربوط به سیستم عامل های عمومی می شود.
معماری vSphere به فضای کمتری نسبت به محصولات پیشنهادی رقیبانش نیاز دارد. حجم کمتر vSphere باعث می شود که راه های کمتری برای حمله هکر ها وجود داشته باشد.
سرور مجازی سازی شده ای که مبتنی بر سیستم عامل باشد می تواند بارها منجر به راه اندازی مجدد سرور و ایجاد taskهای سنگین اضافی روی سرور شود. نصب یک پچ امنیتی مهم معمولا با راه اندازی مجدد سیستم همراه است، حتی زمانی که آن پچ به مجازی سازی ربطی نداشته باشد.
با استفاده از vSphere شما مجبور نیستید که زمان با ارزشتان را برای پچ هایی که مربوط به مجازی سازی نیستند صرف کنید.
4 – همیشه در دسترس
VMware vSphere به همراه operations management برای ارائه ی عملکرد و دسترس پذیری بهتر به برنامه های حیاتی سازمان طراحی شده است. مجموعه ای از ویژگی ها متمرکز شده اند تا مطمئن شوند که برنامه ها بهترین عملکرد ممکن را بر اساس سیاست های شما ارائه می دهند.
چند نمونه از اجزای نرم افزاری که دسترسی پذیری بالایی را ارائه می کنند:
- هنگامی که یک سرور یا سیستم عامل از کار می افتد، (High availability (HA در VMware vSphere ماشین هایی که تحت تاثیر قرار گرفته اند را راه اندازی مجدد می کند. اگر یک سرور از کار بیافتد vSphere HA به صورت خودکار ماشین های مجازی ای که از کارافتاده اند را در سرور های دیگر که مانند سخت افزار یدکی عمل می کنند، راه اندازی مجدد می کند. زمانی که یک سیستم عامل از کار بیافتد، vSphere HA ماشین مجازی از کار افتاده را در همان سرور راه اندازی مجدد می کند.
- HA در VMware vSphere حتی سطح بالاتری از دسترس پذیری را ارائه می کند به طوریکه به vSphere این امکان را می دهد که برنامه های از کار افتاده را شناسایی کند و انها را در اخرین حالتی که از کار افتاده اند، بازیابی کند. HA از تعداد زیادی از برنامه های رایج پشتیبانی می کند و می تواند از طریق API به اکوسیستم VMware گسترش یابد.
- DRS در VMware vSphere، اختصاص منابع به ماشین های مجازی در کلاستر و load balancing را با توجه به سیاست های اتوماسیون سازمان برای کاهش پیچیدگی مدیریت ارائه می کند.
- Storage DRS در VMware vSphere، قابلیت load balancing را خودکار می کند و از ویژگی های استوریج استفاده می کند تا بهترین مکان را برای جای دادن اطلاعات مربوط به ماشین های مجازی در زمانی که ایجاد می شوند و یا در هنگام استفاده، شناسایی کنند.
5 – بازیابی اطلاعات از دست رفته
زمانی که کسب و کار شما به برنامه هایتان وابسته است، به ابزارهایی نیاز دارید که این امکان را بدهد تا اگر مشکلی در سیستم های شما به وجود آمد بتوانید اطلاعات را به سرعت بازیابی کنید. قابلیت های مهمی را برای راهکار های بازیابی اطلاعات در مجموعه ی vSphere خواهید یافت، که یکی از آنهاVMware vSphere Replication نام دارد.
VMware vSphere Replication ماشین های مجازی را در سرور های دیگر کپی می کند ، زمانی که نیاز به انها احساس شود آنها را برای بازیابی دردسترس قرار می دهد.
یکی دیگر از گزینه هایی که VMware برای دستیابی به کسب و کاری پایدار ارائه می کند ، disaster recovery است که به عنوان یک سرویس ارائه می شود. با استفاده از VMware vCloud Air شما می توانید بدون پرداخت هزینه های لازم برای خرید تجهیزات و نرم افزار های مورد نیاز برای disaster recovery، مزایای بازیابی اطلاعات را از مکانی خارج از سازمانتان دریافت کنید.
جمع بندی
VMware vSphere به همراه operation management پنج ویژگی ضروری را برای محیط های مجازی سازی شما ارئه می کند:
- تکنولوژی اثبات شده
- مدیریت یکپارچه
- قابلیت اطمینان
- دسترس پذیری بالا
- بازیابی اطلاعات
این ویژگی ها می توانند به شما کمک کنند تا برنامه هایتان را در سطح بالاتری از سطح خدمات اجرا کنید، از طریق مدیریت بهتر ظرفیت ها صرفه جویی کنید و برنامه های حیاتی سازمان را حتی زمانی که مشکلاتی برای سازمانتان به وجود می آید، در وضعیت دسترس پذیری بالا نگه دارید.
- proven technology
- reliability
- high availability
پروتکل STP چیست و چگونه کار می کند؟
Spanning Tree Protocol
سوئیچ های سیسکو با استفاده از پروتکل STP، از به وجود آمدن loop در شبکه جلوگیری می کنند. در یک LAN که دارای مسیر های redundant می باشد، اگر پروتکل STP فعال نباشد، باعث به وجود آمدن یک loop نامحدود در شبکه می شود. اگر در همان LAN پروتکل STP را فعال کنید، سوئیچ ها برخی از پورت ها را بلاک می کنند و اجازه نمی دهند اطلاعات از آن پورت ها عبور کنند.
پروتکل STP با توجه به دو معیار پورت ها را برای بلاک کردن انتخاب می کند:
• تمامی deviceهای موجود در LAN بتوانند با هم ارتباط برقرار کنند. درواقع STP تعداد پورت های کمی را بلاک می کند تا LAN به چند بخش که نمی توانند با هم ارتباط برقرار کنند، تقسیم نشود.
• Frame ها بعد از مدتی drop می شوند و به طور نامحدود در loop قرار نمی گیرند.
پروتکل STP تعادلی را در شبکه به وجود می آورد بطوریکه frame ها به هر کدام از device ها که لازم باشد می رسند بدون اینکه مشکلات loop به وجود آید.
پروتکل STP با چک کردن هر interface قبل از اینکه از طریق آن اطلاعات ارسال کند، از به وجود آمدن loop جلوگیری می کند. در این روند چک کردن اگر آن پورت داخل VLAN خود در وضعیت STP forwarding باشد، از آن پورت در حالت عادی استفاده می کند، اما اگر در وضعیت STP blocking باشد، ترافیک تمام کاربران را بلاک می کند و هیچ ترافیکی در آن VLAN را از آن پورت عبور نمی دهد.
توجه کنید که وضعیت STP یک پورت، اطلاعات دیگر مربوط به پورت را تغییر نمی دهد. برای مثال با تغییر وضعیت خود تغییری در وضعیت trunk/access و connected/notconnect ایجاد نمی کند. وضعیت STP یک مقدار جدا از وضعیت های قبلی دارد و اگر در حالت بلاک باشد پورت را از پایه غیر فعال می کند.
نیاز به پروتکل STP
پروتکل STP از وقوع سه مشکل رایج در LANهای Ethernet جلوگیری می کند. در نبود پروتکل STP ، بعضی از frame های Ethernet برای مدت زیادی (ساعت ها، روز ها و حتی برای همیشه اگر deviceهای LAN و لینک ها از کار نیوفتند) در یک loop داخل شبکه قرار می گیرند. سوئیچ های سیسکو به طور پیش فرض پروتکل STP را اجرا می کنند. توصیه می کنیم پروتکل STP را تا زمانی که تسلط کامل به آن ندارید، غیر فعال نکنید.
اگر یک frame درloop قرار بگیرد Broadcast storm به وجود می آید. Broadcast storm زمانی به وجود می آید که هر نوعی از frameهای Ethernet (مانند multicast frame،broadcast frame و unicast frameهایی که مقصدشان مشخص نیست) در loop بی نهایت داخل LAN قرار بگیرند. Broadcast stormها می توانند لینک های شبکه را با کپی های به وجود آمده از یک frame اشباع کنند و باعث از بین رفتن frameهای مفید شوند، و نیز با توجه به بار پردازشی مورد نیاز برای پردازش broadcast frameها، تاثیر قابل ملاحظه ای روی عملکرد deviceهای کاربران دارند.
تصویر 1-2 یک مثال ساده از Broadcast storm را نشان می دهد که در آن سیستمی که Bob نام دارد یک broadcast frame ارسال می کند. خط چین ها نحوه ارسال frameها توسط سوئیچ ها را در نبود STP نمایش می دهند.
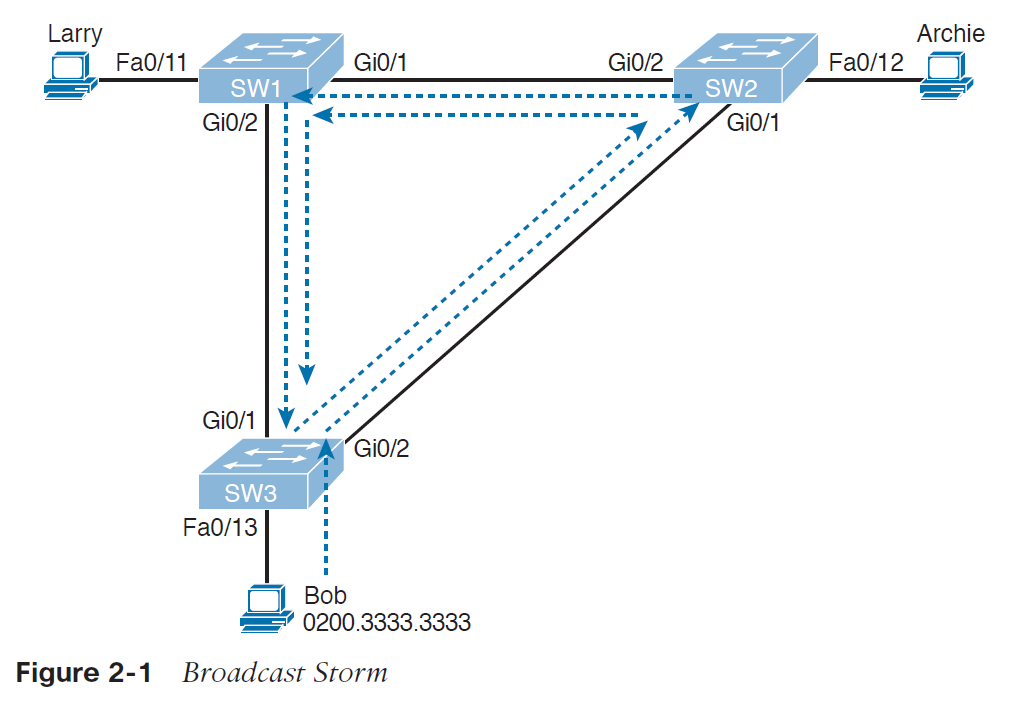
در تصویر 1-2، frameها در جهت های مختلفی می چرخند، برای ساده تر شدن مثال فقط در یک جهت آنها را نمایش داده ایم.
در مفاهیم سوئیچ، سوئیچ ها در ارسال کردن broadcast farmeها، frameها را به تمام پورت ها به جز پورت فرستنده آن frame، ارسال می کنند. در تصویر 1-2، سوئیچ SW3، frame را به سوئیچ SW2 ارسال می کند، سوئیچ SW2 آن را برای سوئیچ SW1 ارسال می کند، سوئیچ SW1 نیز آن را برای SW3 ارسال می کند و به همین ترتیب این frame به سوئیچ SW2 ارسال می شود و داخل یک loop می چرخد.
زمانی که یک Broadcast storm اتفاق می افتد، frame ها مانند مثال بالا به چرخیدن ادامه می دهند تا زمانی که تغییراتی به وجود آید (شخصی یکی از پورت ها را خاموش کند، سوئیچ را reload کند یا کاری کند که loop از بین برود).
Broadcast storm همچنین باعث به وجود آمدن مشکل نا محسوسی به نام MAC table instability یا ناپیوستگی جدول مک می شود. MAC table instability بدین معنا است که جدول مک آدرس پیوسته در حال تغییر کردن می باشد، و علت آن این است کهframe هایی با مک آدرس یکسان از پورت های مختلفی وارد سوئیچ ها می شوند. به مثال زیر توجه کنید:
در تصویر 1-2 در ابتدا سوئیچ SW3 مک آدرس باب را که از طریق پورت Fa0/13 وارد سوئیچ شده، به جدول مک آدرس خود اضافه می کند:
0200.3333.3333 Fa0/13 VLAN 1
حالا فرایند switch learning را در نظر بگیرید در زمانی که frame در حال چرخش از سوئیچSW3 به سوئیچ SW2 ، سپس به سوئیچ SW1 و بعد از آن از طریق پورت G0/1 وارد سوئیچ SW3 می شود. سوئیچ SW3 می بیند که مک آدرس مبداء 0200.3333.3333 می باشد و از پورت G0/1 وارد سوئیچ شده است، جدول مک آدرس خود را به روز می کند:
0200.3333.3333 G0/1 VLAN 1
در این مورد سوئیچ SW3 هم دیگر نمی تواند به درستی frameها را به مک آدرس باب برساند. اگر در این حالت یک frame (خارج از frameهایی که در داخل loop افتاده اند) به سوئیچ SW3 برسد که مقصد آن باب باشد، سوئیچ SW3 اشتباها frame را روی پورت G0/1 به سوئیچ SW1 ارسال می کند، که این موضوع ترافیک زیادی را به وجود می آورد.
سومین مشکلی که Frame های در حال چرخش در یک broadcast storm ایجاد می کنند این است که کپی های مختلفی از یک frame به دست گیرنده می رسد. در تصویر 1-2 فرض کنید که باب یک frame را برای لاری ارسال کند در حالی که هیچ کدام از سوئیچ ها مک آدرس لاری را نمی دانند. سوئیچ ها frameها را به صورت unicast هایی که مک آدرس مقصدشان مشخص نیست، ارسال می کنند. زمانی که باب یک frame که مک آدرس مقصدش لاری است را ارسال می کند، سوئیچSW3 یک کپی از آن را به سوئیچ های SW1 و SW2 ارسال می کند. سوئیچ های SW1 و SW2 نیز frame را broadcast می کنند، این کپی ها باعث می شود که آن frame در داخل یک loop قرار گیرد. سوئیچ SW1 همچنین یک کپی از frame را به پورت Fa0/11 برای لاری ارسال می کند. در نتیجه لاری کپی های مختلفی از آن frame را دریافت می کند، که می تواند باعث از کار افتادن برنامه ای در سیستم لاری و یا مشکلات شبکه ای شود.
جدول زیر خلاصه ای از سه مشکل اساسی در شبکه ای که دارای redundancy است و STP در آن اجرا نمی شود را نشان می دهد:
پروتکل (STP (IEEE 802.1D دقیقا چه کار می کند؟
پروتکلSTP با قرار دادن هر یک از پورت های سوئیچ در وضعیت های forwarding و blocking از به وجود آمدن loop جلوگیری می کند. پورت هایی که در وضعیت forwarding هستند به صورت عادی فعالیت می کنند، frameها را ارسال و دریافت می کنند. اما پورت هایی که در وضعیت blocking قرار دارند به جز پیام های مربوط به پروتکل STP (و برخی دیگر از پیام هایی که برای پروتکل ها استفاده می شوند) ، هیچ frame دیگری را پردازش نمی کنند. این پورت ها frameهای کاربران را ارسال نمی کنند، مک آدرس frameهای ورودی را ذخیره نمی کنند و frameهای دریافتی از کاربران را نیز پردازش نمی کنند.
تصویر 2-2 راه حل استفاده از پروتکل STP (قرار دادن یکی از پورت های سوئیچ SW3 در وضعیت blocking) در مثال پیشین را نمایش می دهد:
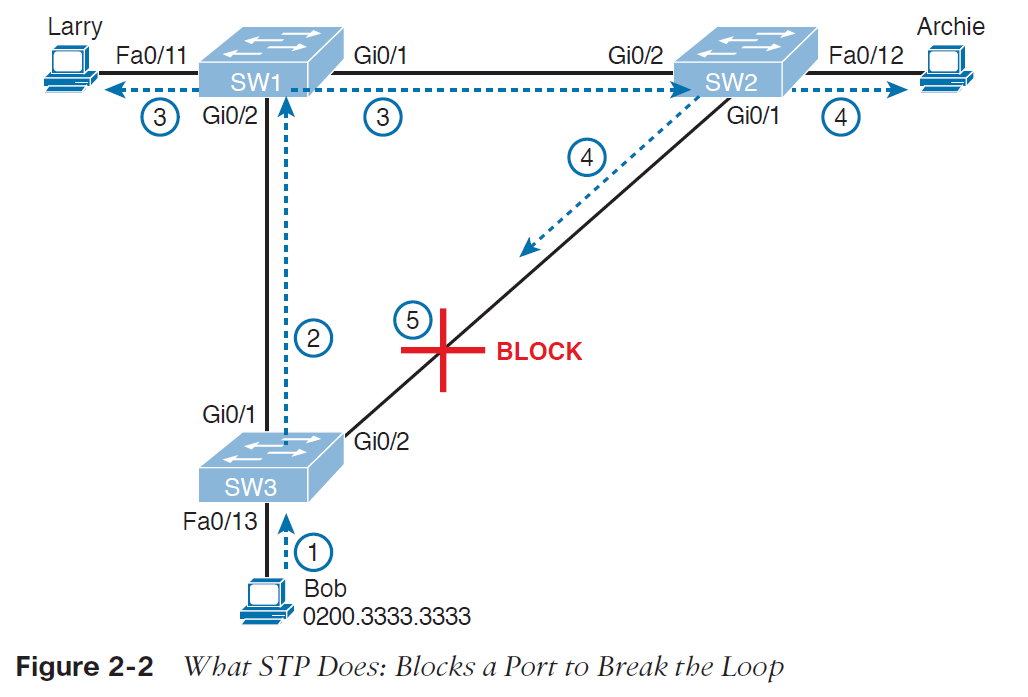
همانطور که در مراحل زیر نشان داده شده، زمانی که باب یک broadcast را ارسال می کند، دیگر loop به وجود نمی آید:
• مرحله اول: باب frame را به سوئیچ SW3 ارسال می کند.
• مرحله دوم: سوئیچ SW3 این frame را فقط به سوئیچ SW1 ارسال می کند، دیگر به سوئیچ SW2 ارسال نمی شود چون پورت G0/2 در وضعیت blocking قرار دارد.
• مرحله سوم: سوئیچ SW1 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله چهارم: سوئیچ SW2 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله پنجم: سوئیچ SW3 به صورت فیزیکی یک frame را دریافت می کند، اما frame دریافتی از SW2 را به دلیل اینکه پورت G0/2 در سوئیچ SW3 در وضعیت blocking قرار دارد، نادیده می گیرد.
با استفاده از توپولوژی STP در تصویر 2-2، سوئیچ ها از لینک موجود بین SW2 و SW3 برای انتقال ترافیک استفاده نمی کنند. با این حال، اگر لینک بین SW3 و SW1 دچار مشکل شود، پروتکل STP پورت G0/2 را از وضعیت blocking به وضعیت forwarding تغییر می دهد و سوئیچ ها می توانند از آن لینکredundant استفاده کنند. در این موقعیت ها پروتکل STP با انجام فرایند هایی متوجه تغییرات در توپولوژی شبکه می شود و تشخیص می دهد که پورت ها نیاز به تغییر در وضعیتشان دارند و وضعیت آن ها را تغییر می دهد.
سوالاتی که احتمالا زهن شما را نیز مشغول کرده: پروتکل STP چگونه پورت ها را برای تغییر وضعیت انتخاب می کند و چرا این کار را می کند؟ چگونه وضعیت blocking را برای بهره مندی از مزایای لینک های redundant، به وضعیت forwarding تغییر می دهد؟ در ادامه به این سوالات پاسخ خواهیم داد.
پروتکل STP چگونه کار می کند؟
الگوریتم STP یک درخت پوشا (spanning tree) از پورت هایی که frameها را ارسال می کنند تشکیل می دهد. این ساختار درختی، مسیرهایی را برای رسیدن لینک های ethernet به هم مشخص می کند. (مانند پیمودن یک درخت واقعی که از ریشه درخت شروع می شود و تا برگ ها ادامه دارد)
توجه: STP قبل از اینکه در سوئیچ های LAN استفاده شود، در Ethernet bridgeها به کار رفته بود.
STP از فرایندی که بعضا spanning-tree algorithm)STA) نامیده می شود، استفاده می کند که در آن پورت هایی که باید در وضعیت forwarding قرار بگیرند را انتخاب می کند. STP پورت هایی که برای forwarding انتخاب نشدند را در وضعیت blocking قرار می دهد. در واقع پروتکل STP پورت هایی که در ارسال کردن اطلاعات باید فعال باشند را انتخاب می کند و پورت های باقی مانده را در وضعیت blocking قرار می دهد.
پروتکل STP برای قرار دادن پورت ها در حالت forwarding از سه مرحله استفاده می کند:
• پروتکل STP یک سوئیچ را به عنوان root انتخاب می کند و تمام پورت های فعال در آن سوئیچ را در وضعیت forwarding قرار می دهد.
• در هر کدام از سوئیچ های nonroot (همه ی سوئیچ ها به جز root)، پورتی که کمترین هزینه را برای رسیدن به سوئیچ root دارد (root cost)، به عنوان root port(RP) انتخاب می کند و آن ها را در وضعیت forwarding قرار می دهد.
• تعداد زیادی سوئیچ می توانند به یک بخش از Ethernet متصل شوند، اما در شبکه های مدرن، معمولا دو سوئیچ به هر لینک (بخش) متصل می شوند. در بین سوئیچ هایی که به یک لینک مشترک متصل هستند، پورت سوئیچی که root cost کمتری دارد در وضعیت forwarding قرار می گیرد. این سوئیچ ها را designated switch می نامند و پورت هایی که در وضعیت forwarding قرار گرفته را designated port)DP) می نامند.
باقی پورت ها در وضعیت blocking قرار می گیرند.
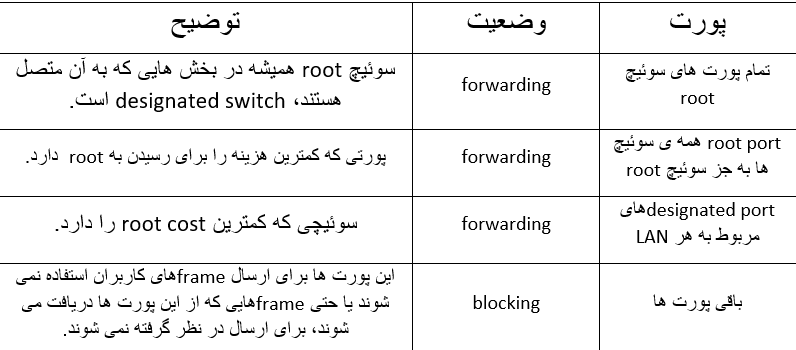
خلاصه ای از علت قرار گرفتن پورت ها در وضعیت های blocking و forwarding توسط پورتکل STP
Bridge و Hello BPDU
فرایند STA با انتخاب یک سوئیچ به عنوان root شروع می شود. برای اینکه روند انتخاب را بهتر متوجه شوید، شما باید با مفهوم پیام هایی که بین سوئیچ ها تبادل می شود به خوبی آشنا شوید و با فرمت شناساگری که برای شناسایی هر سوئیچ استفاده می شود آشنا باشید.
(STP bridge ID (BID یک مقدار 8 بایتی برای شناسایی هر سوئیچ می باشد. Bridge ID به دو بخش 2 بایتی که مشخص کننده اولویت و حق تقدم است و 6 بایتی که system ID نامیده می شود و همان مک آدرس هر سوئیچ است، تقسیم می شود. استفاده از مک آدرس این اطمینان را می دهد که bridge ID هر سوئیچ یکتا خواهد بود.
پیام هایی که برای تبادل اطلاعات مربوط به پروتکل STP بین سوئیچ ها استفاده می شود، bridge protocol data units )BPDU) نام دارد. رایج ترین BPDU ، که hello BPDU نام دارد، تعدادی از اطلاعات که شامل BID سوئیچ ها نیز می شود را لیست می کند و ارسال می کند. با استفاده از BID درج شده روی هر پیام، سوئیچ ها می توانند تشخیص دهند که هر پیام Hello BPDU از طرف کدام سوئیچ است.
جدول زیر اطلاعات کلیدی مربوط به Hello BPDU را نشان می دهد:
انتخاب سوئیچ root
سوئیچ ها با استفاده از BIDهای موجود در پیام های BPDU، سوئیچ root را انتخاب می کنند. سوئیچی که عدد BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. با توجه به اینکه بخش اول عدد BID مقدار اولویت می باشد، سوئیچی که مقدار اولویت پایین تری داشته باشد به عنوان سوئیچ root انتخاب می شود. برای مثال اگر سوئیچ های اول و دوم به ترتیب دارای اولویت های 4096 و 8192 باشند، بدون در نظر گرفتن مک آدرس سوئیچ ها که در به وجود آمدن BID هر سوئیچ موثر است، سوئیچ اول به عنوان سوئیچ root انتخاب خواهد شد.
اگر مقدار اولویت دو سوئیچ برابر شد، سوئیچی که مک آدرس آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. در این حالت به علت یکتا بودن مک آدرس، حتما یک سوئیچ انتخاب خواهد شد. پس اگر مقدار اولویت دو سوئیچ برابر باشد و مک آدرس آنها 0200.0000.0000 و 0911.1111.1111 باشد، سوئیچی که دارای مک آدرس 0200.0000.0000 است، به عنوان سوئیچ root انتخاب می شود.
مقدار اولویت مضربی از 4096 است و به صورت پیش فرض برای همه ی سوئیچ ها مقدار 32768 را دارد. از آنجایی که مک آدرس سوئیچ ها معیار مناسبی برای انتخاب سوئیچ root نمی باشد بهتر است به صورت دستی مقدار اولویت را تغییر دهیم تا سوئیچی که می خواهیم به عنوان سوئیچ root انتخاب شود.
در فرایند انتخاب سوئیچ root، سوئیچ ها از طریق فرستادن پیام های Hello BPDU که BID خود را در این پیام ها به عنوان root BID قرار داده اند، سعی می کنند خود را به عنوان سوئیچ root به سوئیچ های مجاور خود معرفی کنند. اگر یک سوئیچ پیامی را دریافت کند که BID کمتری نسبت به BID خودش داشته باشد، آن سوئیچ دیگر خود را به عنوان سوئیچ root معرفی نمی کند، به جای آن شروع به ارسال پیام دریافتی که دارای BID بهتری است می کند (مانند رقابت های انتخاباتی که یک نامزد به نفع نامزد هم حزبش که موقعیت بهتری دارد، از رقابت در انتخابات خارج می شود). در نهایت تمامی سوئیچ ها به یک نظر نهایی می رسند که کدام سوئیچ BID کمتری دارد و همه آن سوئیچ را به عنوان سوئیچ root انتخاب می کنند.
توجه : در مقایسه دو پیام Hello با هم، پیامی که BID کمتری دارد، superior Hello و پیامی که BID بیشتری دارد، inferior Hello نام دارد.
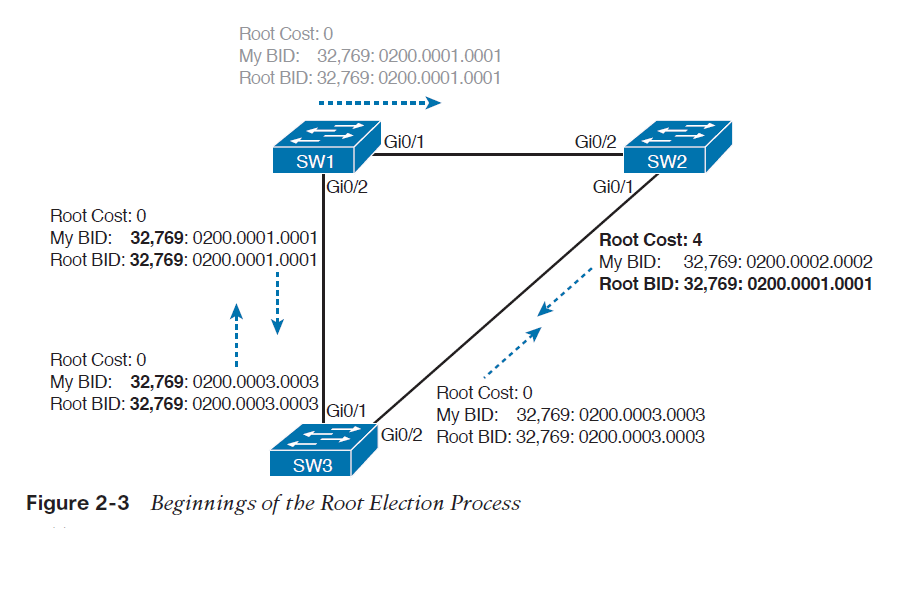
تصویر 3-2 آغاز فرایند انتخاب سوئیچ root را نشان می دهد، در ابتدای این فرایند SW1 همانند باقی سوئیچ ها خود را به عنوان سوئیچ root معرفی می کند. SW2 پس از دریافت Hello مربوط به SW1 متوجه می شود که SW1 شرایط بهتری را برای root بودن دارد، پس شروع به ارسال Hello دریافتی از SW1 می کند. در این حالت سوئیچ SW1 خود را به عنوان root معرفی می کند و SW2 نیز با آن موافقت می کند اما سوئیچ SW3 هنوز سعی می کند که خود را به عنوان سوئیچ root معرفی کند و Hello BPDUهای خود را ارسال می کند.
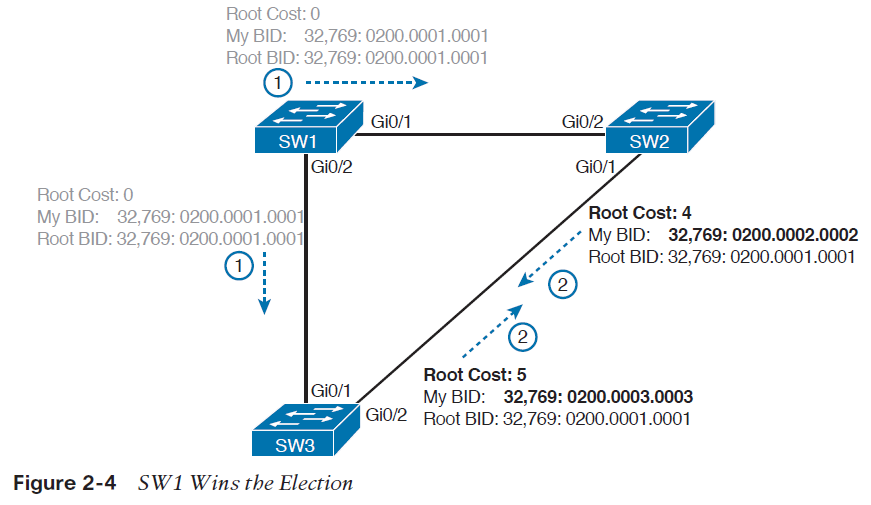
دو نامزد هنوز باقی ماندند:SW1 و SW3. از آنجایی که SW1 مقدار BID کمتری دارد، SW3 پس از دریافت BPDU مربوط به SW1، SW1 را به عنوان سوئیچ root می پذیرد و به جای BPDU خود، BPDU دریافتی از SW1 را به سوئیچ های مجاور ارسال می کند.
پس از اینکه فرایند انتخاب تکمیل شد، فقط سوئیچ root به تولید پیام های Hello BPDU ادامه می دهد. سوئیچ های دیگر این پیام ها را دریافت می کنند و BID فرستنده و root costرا تغییر می دهند و به باقی پورت ها ارسال می کنند. در تصویر 4-2، در قدم اول سوئیچ SW1 پیام های Hello را ارسال می کند، در قدم دوم سوئیچ های SW2 و SW3 به صورت مستقل تغییرات را روی پیام های دریافتی اعمال می کنند و آن ها را روی پورت های خود ارسال می کنند.
برای اینکه بخواهیم مقایسه BID را خلاصه کنیم، BID را به بخش های تشکیل دهنده ان تقسیم می کنیم، سپس به صورت زیر مقایسه می کنیم:
• اولویتی که کمترین مقدار را دارد
• اگر مقدار اولویت آن ها برابر باشد، سوئیچی که مک ادرسش کمترین مقدار را دارد
انتخاب Root Port برای هر سوئیچ
در مرحله ی بعدی، پس از انتخاب سوئیچ root، پروتکل STP برای سوئیچ های nonroot (همه ی سوئیچ ها به جز سوئیچ root) یک root port )RP) انتخاب می کند. RP هر سوئیچ، پورتی است که کمترین هزینه را برای رسیدن به سوئیچ root دارد.
احتمالا عبارت هزینه برای همه ی ما در انتخاب مسیر بهتر، روشن و مشخص باشد. اگر به دیاگرام شبکه ای که در آن سوئیچ root و هزینه ارسال اطلاعات روی هر پورت مشخص باشد توجه کنید، می توانید هزینه برقراری ارتباط با سوئیچ root را برای هر پورت به دست آورید. توجه کنید که سوئیچ ها برای به دست آوردن هزینه برقراری ارتباط با سوئیچ root، از دیاگرام شبکه استفاده نمی کنند، صرفا استفاده از آن برای درک این موضوع به ما کمک می کند.
تصویر 5-2 همان سوئیچ های مثال پیشین که در آن سوئیچ root و هزینه ی رسیدن به سوئیچ root را برای پورت های سوئیچ SW3 نشان می دهد.
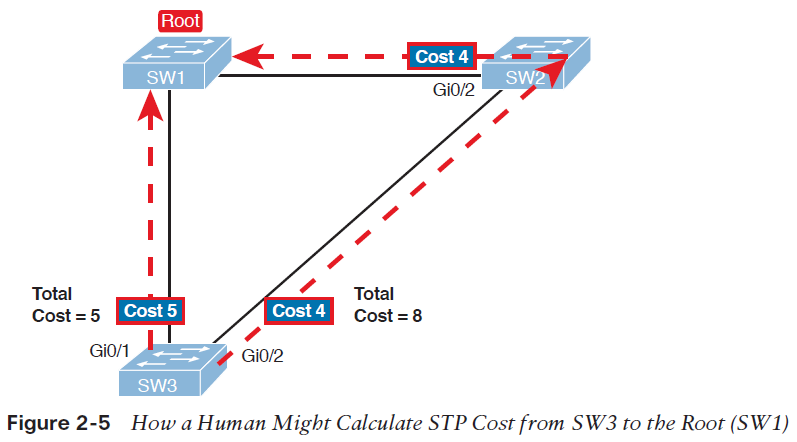
سوئیچ SW3 برای ارسال frameها به سوئیچ root، می تواند از دو مسیر استفاده کند: مسیر مستقیم که از پورت G0/1 خارج می شود و به سوئیچ root می رسد، و مسیر غیر مستقیمی که از پورت G0/2 خارج می شود و از طریق SW2 به سوئیچ root می رسد. برای هر یک از پورت ها، هزینه ی رسیدن به سوئیچ root برابر است با مجموع هزینه ی خروج از پورت هایی که frame ارسالی، برای رسیدن به سوئیچ root از آن ها عبور می کند (در این محاسبه، هزینه ورود آن frame به پورت ها حساب نمی شود). همانطور که مشاهده می کنید، مجموع هزینه ی مسیر مستقیم که از پورت G0/1 سوئیچ SW3 خارج می شود برابر 5 است، و مسیر دیگر دارای مجموع هزینه ی 8 می باشد. از آنجایی که پورت G0/1، بخشی از مسیری است که هزینه ی کمتری برای رسیدن به سوئیچ root دارد، سوئیچ SW3 این پورت را به عنوان root port انتخاب می کند.
سوئیچ ها با سپری کردن فرایندی متفاوت به همین نتیجه می رسند. آنها هزینه خروج از پورت خود را به root cost موجود در Hello BPDU ورودی از همان پورت اضافه می کنند و هزینه رسیدن به سوئیچ root از طریق آن پورت را به دست می آورند. هزینه خروج از هر پورت در پروتکل STP یک عدد صحیح (integer) می باشد که به هر پورت در هر VLAN اختصاص می یابد، تا پروتکل STP با استفاده از این مقیاس اندازه گیری بتواند تصمیم بگیرد که کدام پورت را به توپولوژی خود اضافه کند. در این فرایند سوئیچ ها، root cost سوئیچ های مجاور را که از طریق Hello BPDUهای دریافتی به دست می آورند، بررسی می کنند.

تصویر 6-2 یک مثالی از چگونگی محاسبه بهترین root cost و سپس انتخاب آن به عنوان root port را نشان می دهد. اگر به تصویر توجه کنید، خواهید دید که سوئیچ root پیام هایی(Hello) که root cost آن ها برابر صفر می باشد را ارسال می کند. هزینه رسیدن به سوئیچ root از طریق پورت های سوئیچ root برابر با صفر است.
در ادامه به سمت چپ تصویر توجه کنید که سوئیچ SW3، root cost دریافتی از طریق SW1 را (که برابر صفر است) با هزینه ی خروج از پورت G0/1 که آن Hello را دریافت کرده (5) جمع می کند و هزینه ارسال اطلاعات از طریق این پورت را به دست می آورد.
در سمت راست تصویر، سوئیچ SW2 متوجه شده که root cost آن برابر با 4 است. پس زمانی که SW2 یک Hello برای SW3 ارسال می کند، مقدار root cost آن را 4 قرار می دهد. در سمت دیگرهزینه ارسال اطلاعات از طریق پورت G0/2 در سوئیچ SW3 برابر 4 است، از اینرو سوئیچ SW3 این دو مقدار را با هم جمع می کند و به این نتیجه می رسد که هزینه ی رسیدن به سوئیچ root از طریق پورت G0/2 برابر 8 است.
با توجه به نتایج به دست آمده از آنجایی که پورت G0/1 نسبت به پورت G0/2 هزینه ی کمتری برای رسیدن به سوئیچ root دارد، پس سوئیچ SW3 پورت G0/1 را به عنوان RP انتخاب می کند. سوئیچ SW2 نیزبا گذراندن همین فرایند پورت G0/2 را به عنوان RP انتخاب می کند. سپس تمام سوئیچ ها، root port های خود را در وضعیت forwarding قرار می دهند.
انتخاب Designated Port در هر LAN segment (پورت کاندید)
پس از انتخاب سوئیچ root، در سوئیچ های nonroot، تمام root portها را مشخص کردیم و آنها را در وضعیت forwarding قرار دادیم. مرحله نهایی پروتکل STP برای تکمیل توپولوژی STP، انتخاب designated port در هر LAN segment است. در هر بخش(segment) از LAN، پورت سوئیچی که کمترین root cost را دارد و به آن بخش از LAN متصل است Designated port )DP) نامیده می شود. زمانی که یک سوئیچ nonroot می خواهد که یک Hello را ارسال کند، هزینه رسیدن به سوئیچ root را در root cost آن پیام قرار می دهد و ارسال می کند. دراینصورت پورت سوئیچی که کمترین هزینه را برای رسیدن به root دارد، در میان تمام سوئیچ هایی که به آن بخش متصل هستند، به عنوان DP در آن بخش شناخته می شود. در این مرحله اگر هزینه سوئیچ ها برای رسیدن به سوئیچ root برابر بود، پورت سوئیچی که BID کمتری دارد را به عنوان DP انتخاب می کنیم.
در تصویر 4-2 پورت G0/1 در سوئیچ SW2 که به سوئیچ SW3 متصل است، به عنوان DP انتخاب می شود.
پس از انتخاب DPها، تمام آن ها را در وضعیت forwarding قرار می دهیم.
مثالی که در تصاویر 3-2 تا 6-2 به نمایش گذاشته شد، تنها پورتی که نیازی ندارد تا در وضعیت forwarding قرار بگیرد، پورت G0/2 در سوئیچ SW3 است. درنهایت فرایند پروتکل STP کامل شد و جدول زیر وضعیت نهایی هر پورت و علت قرار گرفتن در آن وضعیت را نشان می دهد:
به صورت خلاصه اگر بخواهیم توضیح دهیم، در فرایند اجرای پروتکل STP:
• در قدم اول سوئیچ root انتخاب می شود که ابتدا تمام سوئیچ ها سعی می کنند خود را به عنوان root معرفی کنند، سپس سوئیچی که رقم BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب خواهد شد.
• در قدم دوم برای هر سوئیچ، پورتی که کمترین هزینه برای رسیدن به سوئیچ root دارد را به عنوان root port انتخاب می شود. سپس همه ی root portها را در وضعیت forwarding قرار می گیرند.
• در قدم سوم پورت های کاندید انتخاب می شوند و در وضعیت forwarding قرار می گیرند. در نهایت پورت هایی که وضعیتشان مشخص نشده در وضعیت blocking قرار می گیرند.